FAQs
This FAQ document provides answers to the most common questions about the Syntphony NLP
Frequently asked questions
What is the role of Syntphony NLP in Syntphony CAI?
Syntphony NLP is a NTT DATA proprietary Natural Language Processing engine, responsible for training and the prediction of intents and entities.
What is the difference between intents and entities?
An Intent is a categorization of a user intention, and is usually represented by an action the user wants to take, regarding some information.
An Entity is a group of specific information used to describe or specify an action. Entities are commonly used to disambiguate the information the user is providing the virtual agent. There are three types of Entities provided by Syntphony NLP:
When should I use intents and entities?
It’s recommended to use intents when there is a goal or aim to the user, when typing their messages or questions.
Whenever this action expected by the user has different variations or specific information that needs to be provided to fully understand what he wants, you should use entities.
What types of entities are available in Syntphony NLP?
Synonyms Entities:
Like the name implies, this a text matching entity, when you want to capture especific words or terms. It recognizes semantically words in a category. So, for a given category, like “color”, you can specify color types as values, such as “blue”, “green” or “yellow” and, for each one of those, you can add synonyms, like blue: aqua, navy, or yellow: jaune, amber, gold.
Pattern Entities:
This type of entity is commonly used when there is a specific pattern of information you want to capture from the user's message. A good example is emails. Instead of creating an intent for every possible email, you create a pattern entity that recognizes the structure of an email address.
System Entities:
Pre-built entities offered by Syntphony NLP, Syntphony NLP offers fice system entities: Cardinal (recognizes quantity), Date (recognizes a specific date), Address, Product (recognizes products, from a spoon to a car) and Language.
How does Syntphony NLP calculates the confidence score for intents?
In intent classification tasks, a confidence score represents the likelihood that a given sentence/utterance sent by the user is the correct Intent. This score varies from 0% to 100% and it is distributed across all possible predictions (intents).
How should I tune the confidence score threshold?
The confidence score from Syntphony NLP predictions can vary, depending of various factors:
Unbalanced dataset
Volume of utterances per intent
Quality of intents
It's important to note that this score is directly related to the quality of the dataset created. You can change the confidence score threshold in the Cockpit.
If confidence score varies across all intents, why is that my intent has a 100% confidence score?
In Syntphony NLP, every example of utterances are stored and in a dictionary-like object, which is used to return the intent directly in cases where the user types the exact same utterance. This feature is called exact match.
In that case, since there isn't predictions from the intent classification model, we assume that if the user sends a message that is exactly the same as trained, it has 100% confidence that that is the correct prediction.
What is the pre-processing step in Syntphony NLP?
There is a pre-processing step consisting of:
Removing bad characters
Analyzing bad pattern entities
Our solution also adds the registered examples in a dictionary-like object for the exact match feature.
What about stop words? How does they affect the predictions?
Stop words are words or terms that doesn't add context or more information in a sentence. Example of stop words are:
pronouns
articles
In classic intent classification models, each word needs to be mapped to a specific representation, which leads to a number of problems with typos and the frequency in which stop words appears. Our solution is to use a different approach, which considers not only the words but the sequence in which they appear. In other words, we consider the context when generating those representations and training our model.
Because of that, stop words are a important factor in maintaining that context, thus, we keep them in our solution.
What style of utterances (examples) should I write?
Like abovementioned, context is an important factor in creating a good intent classification model in Syntphony NLP, so it's a good practice to create sentences that have context in them (meaning that a group of examples from an intent should be of the same context).
Using the same logic, it's also recommended to create small/medium size sentences in the training set, instead of those with only one or two words.
What should I do when I have intents that share similarities?
Depends on the case. The rule of thumb in those cases is to use entities to disambiguate between similar sentences, when possible.
In general, it is recommended to understand what is the type of information you are expecting the user to ask for before creating the intents dataset. For example:
Intent "Ask for information". In here you add examples on how a person usually asks for that specific information.
Entities: What type of information is the user talking about
Traffic?
Office Hours?
Education?
If it is inevitable to create similar intents, it's important to validate (using Syntphony CAIautomated tests) the accuracy of the bot (specially for those intents) and the mean confidence score, adjusting its threshold accordingly.
What are the languages supported by Syntphony NLP?
Syntphony NLP has 53 languagens in total. See full list of supported languages
How can I measure the accuracy of my virtual agent?
Usually, you can use the accuracy metric to understand how well your chatbot predicts the correct intent. The accuracy metric is measured as it follows:
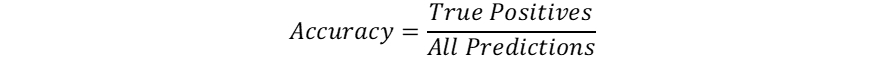
This metric shows how many were actually correct, from all predictions made.
Another way to evaluate the performance of a virtual agent is to look to its performance per intent. Let's examine this example:
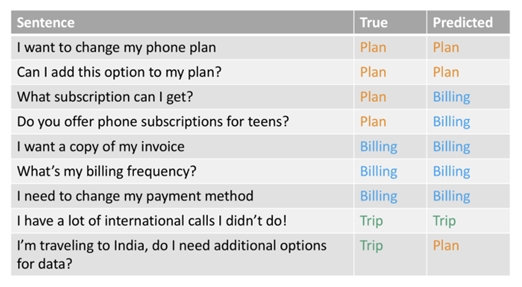
In here we have a validation set where we can see the total correct predictions. Applying the accuracy metric formula here we would have TP=6 from all 9 predictions made, which would give us an accuracy of ~0.66.
If we take into account just the accuracy, this is not a very good result, but it isn't clear where the virtual agent could improve and which intents we should work on in the curation process.
One way to visually understand which intents are affecting the results the most is to use a confusion matrix.
The confusion matrix gives us an overview of predicted intents versus expected intents and it helps us answer questions like “When the expected prediction of a user’s sentence is Plan, what did it actually predict?”.
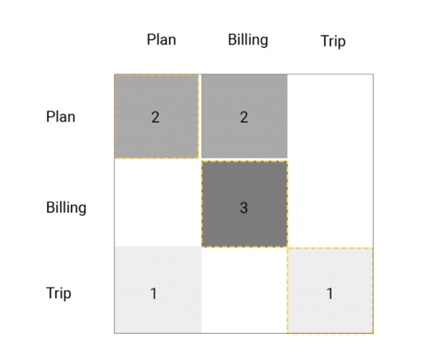
With that, you can see which are the intents that may need to be reviewed in the curation process of the virtual agent.
Does Syntphony NLP controls the flow of conversation?
No, the conversational flows are controlled by the user creating them in the Cockpit.
How do I deal with the rate of false positives in my virtual agent?
False positives in a virtual agent environment can happen in different use cases:
Similar intents trained together can cause confusion for the model prediction, thus, giving a higher rate of false positives.
The recommendation is to understand the way that the conversation is being built so that you have intents created for different contexts and in cases where you need disambiguation, use entities.
User's interactions of a context that wasn’t expected when creating the chatbot
Sometimes the users send messages that are not covered by any of the intents or flows created
Curation of the user's interactions and a periodic validation of the dataset are needed to understand if there is any need to create or modify the current flows and intents.
Unbalanced datasets:
The quality of the prediction is directly related to the quality of the dataset
If there is an intent that has a lot more examples than others, that can make the model biased to make more prediction to the majority class/intent.
We recommend as best practice to maintain an even proportion of examples in each intent to reduce bias.
Last updated
Was this helpful?